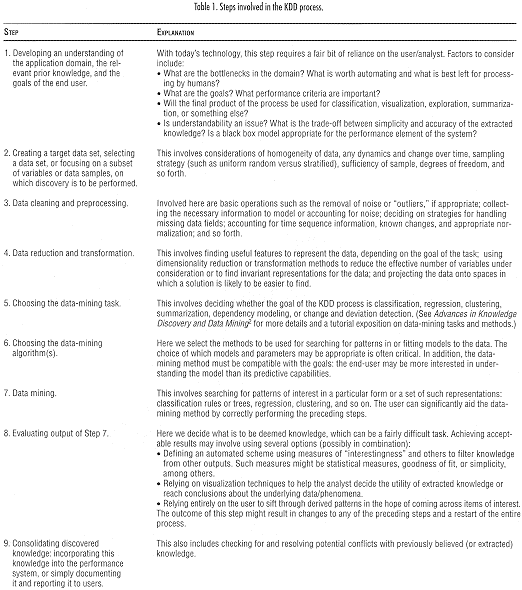
Labels:text | font | paper | screenshot | letter | number | document OCR: Table 1. Steps involved in the KDD process. STE EXPLANATION 1. Developing an understanding of With today's technology, this step requires a fair bit of reliance on the user/analyst. Factors to consider the application domain, the rel- Include: evant prior knowledge, and the . What are the bottlenecks in the domain? What is worth autornating and what is best left for process- goals of the end user. ing by humans? . What are the goals? What performance criteria are important? . Will the final product of the process be used for classification, visualization, exploration, summariza- tion, or something else? . Is understandability an issue? What is the trade-off between simplicity and accuracy of the extracted knowledge? Is a black box model appropriate for the performance element of the system? 2. Creating a target data set, selecting This involves considerations of homogeneity of data, arty dynamics and change over time, sampling a data set, or focusing on a subset strategy (such as uniform random versus stratilied), sufficiency of sample, degrees of freedom, and of variables or data samples, on so forth. which discovery is to he performed. 3. Data cleaning and preprocessing. Involved here are basic operations such as the removal of noise or "outliers," if appropriate; collect- ing the necessary information to model or accounting for noise; deciding on strategies for handling missing data fields; accounting for time sequence information, known changes, and appropriate nor- malization; and so forth. 4. Data reduction and transformation. This involves finding useful features to represent the data, depending on the goal of the task; using dimensionality reduction or transformation methods to reduce the effective number of variables under consideration or to find invariant representations for the data; and projecting the data onto spaces in which a solution is likely to be easier to find. 5. Choosing the data-mining task. This involves deciding whether the goal of the KDD process is classification, regression, clustering, summarization, dependency modeling, of change and deviation detection. (See Advances in Knowledge Discovery and Data Mining for more details and a tutorial exposition on data-mining tasks and methods.) 6. Choosing the data-mining Here we select the methods to be used for searching for patterns in or fitting models to the data. The algorithm(s). choice of which models and parameters may be appropriate is often critical. In addition, the data- mining method must be compatible with the goals: the end-user may be more interested in under- standing the model than its predictive capabilities. 7. Data mining. This involves searching for patterns of interest in a particular form or a set of such representations: classification rules of trees, regression, clustering, and so on. The user can significantly aid the data- mining method by correctly performing the preceding steps. 8. Evaluating output of Step 7. Here we decide what is to be deemed knowledge, which can be a fairly difficult task. Achieving accept- able results may involve using several options (possibly in combination): . Defining an automated scheme using measures of "interestingness" and others to filter knowledge from other outputs. Such measures might be statistical measures, goodness of fit, or simplicity. among others. . Relying on visualization techniques to help the analyst decide the utility of extracted knowledge or reach conclusions about the underlying data/phenomena. . Relying entirely on the user to sift through derived patterns in the hope of coming across items of interest. The outcome of this step might result in changes to any of the preceding steps and a restart of the entire process. 9. Consolidating discovered This also includes checking for and resolving potential conflicts with previously believed (or extracted) knowledge: incorporating this knowledge. knowledge into the performance System, or simply documenting it and reporting it to users.
{kind=link}
{kind=link}